 中文
中文
 English
English
 한국어
한국어
이러한 툴들은 Ubuntu 뿐만 아니라 Linux 계열은 대부분 사용가능하므로, 설치 방법만 조금씩 다를 뿐 사용방법은 동일합니다.
서버가 느리거나 제대로 작동하지않는 것 같다고 생각될 때 여러분들은
무엇부터 하시나요?
증상마다 다르지만 저는 하드웨어 결함 유무부터 확인해봅니다.
쿨러가 제대로 장착되어있지 않거나 서멀구리스가 말라붙어
냉각이 제대로 되지 않을 때 cpu 온도는 올라갑니다.
때문에, 저는 서버가 느리다고 생각될 때 제일 먼저 cpu 온도 측정을 합니다.
1.Cpu 온도 확인 툴 설치(lm-sensors)
sudo apt-get install lm-sensors
sudo sensors-detect --auto
sudo service module-init-tools restart
명령어 : watch sensors
watch sensors 명령어를 입력하면 아래와 같이 부품들의 센서에서 측정된 온도 값들이 나옵니다.
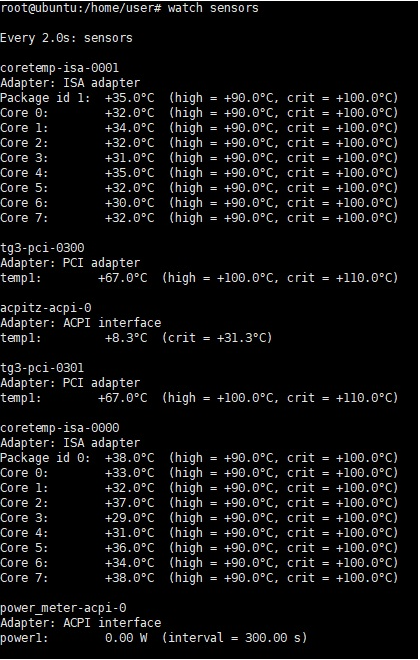
Cpu 기본 온도가 높고 돌아가는 프로세스가 많을 때 과부하가 걸려서
온도가 과하게 높아지면 서버는 자체적으로 온도를 낮추기위해 성능을 저하시킵니다. 때문에 적절한 온도 관리는 서버 관리의 핵심 요소라고 할 수 있죠.
그렇다면 어떤 프로세스가 자원을 많이 잡아먹고 있는지는 어떻게 확인할까요?
2.자원 사용량 모니터링 ( cpu / ram )
sudo apt-get install htop
명령어 : htop
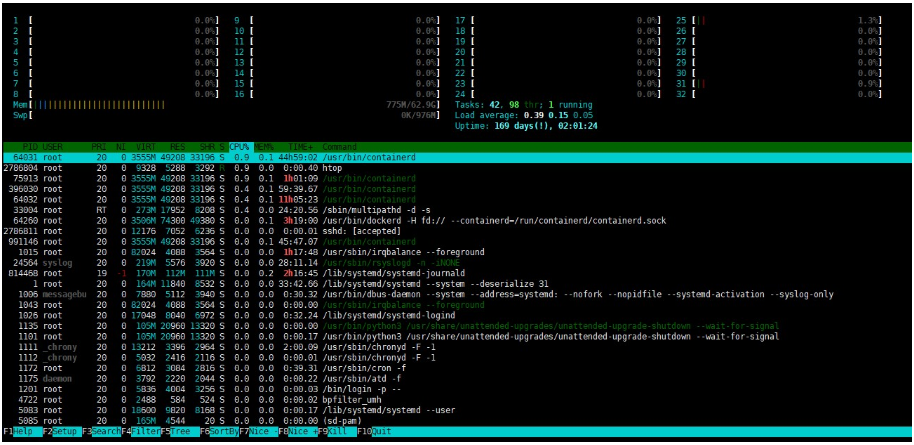
사용자 친화적으로 모니터링을 할 수 있게 해주는 툴이라 많이 애용하는 편입니다.
이 정보를 토대로 어떤 프로세스가 자원을 많이 잡아먹고 있는지 확인이 가능하겠죠, 그리고 그 프로세스가 비정상적으로 자원을 잡아먹고 있다면, 그로 인해 서버가 느려지는 것이라는 걸 알 수 있게 됩니다.
이렇게 서버 내부에서 돌아가는 프로세스와 하드웨어 온도를 체크하셨음에도 문제가 없다면, 다음 단계로 넘어갑니다.
3.디스크 모니터링 (iotop)
sudo apt-get install iotop
명령어 : iotop
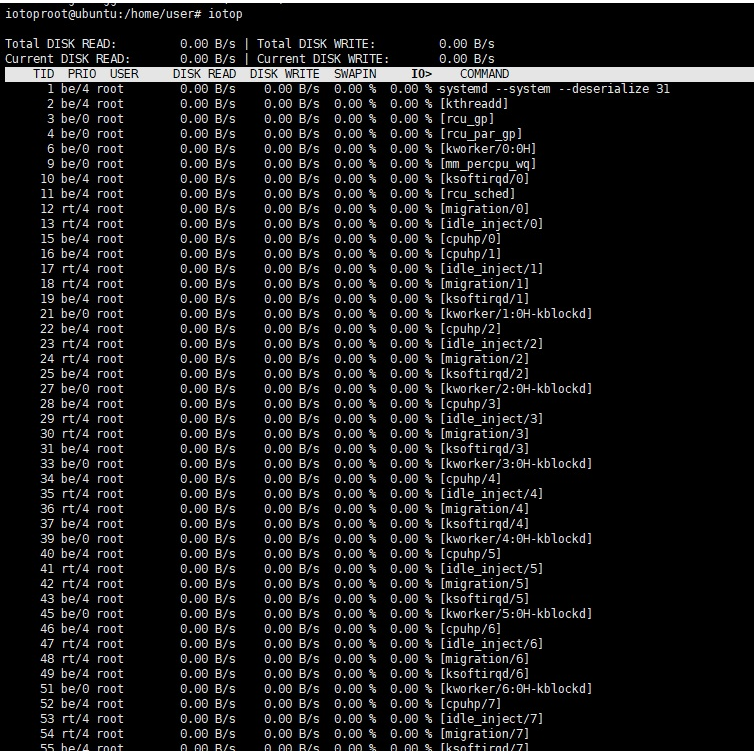
아무런 작업을 안하고있어서 DISK READ 와 DISK WRITE 부분이 변동이 없죠,

아래와 같이 디스크 쓰기 부분이 활성화되는 것을 알 수 있죠.
이것들을 모두 체크한다음
이번엔 네트워크 쪽을 살펴봐야합니다.
4.프로세스 트래픽 모니터링 (nethogs)
sudo apt-get install nethogs
명령어: nethogs (명령 인자를 추가하지 않으면 첫 번째 인터페이스를 모니터링합니다.)
(예: sudo nethogs eth0 / sudo nethogs 인터페이스이름)

그럼 만약 트래픽이 과도하게 발생되고있다면, 이것을 추적하는 방법을 찾아야겠죠?
5.네트워크 트래픽 모니터링(iftop)
sudo apt-get install iftop
명령어: iftop
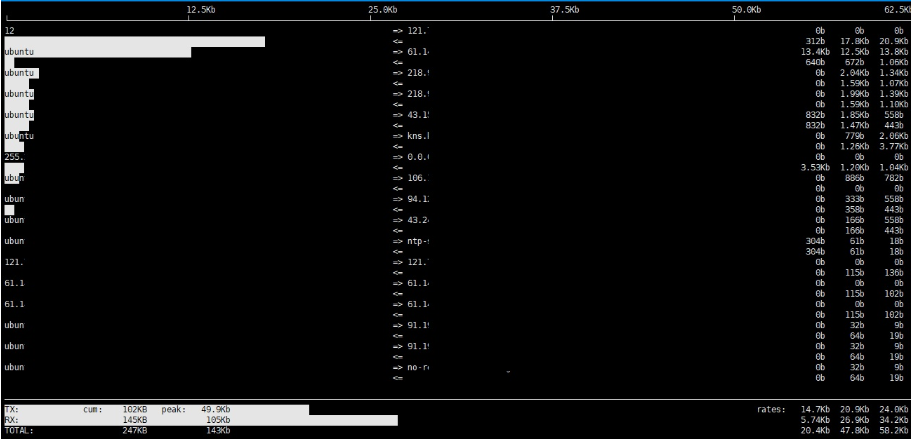
(IP나 도메인 주소 같은 민감정보는 가렸습니다.)
보시면 어디에서 트래픽이 출발해서 어디에서 트래픽이 들어오는지
추적이 가능합니다.
위 정보들을 토대로 근본적인 원인을 찾고 해당 서비스의 로그분석등을 통해 원인을 찾아나갈 수 있게 됩니다.

